
Lo scopo di questa presentazione oggi ad IDEM è quella di esaminare le prime risposte delle biblioteche digitali all’opportunità di coinvolgimento nel ciclo della ricerca, con servizi di supporto che possano facilitare la comunità accademica e il raggiungimento degli obiettivi istituzionali.
Una visione ristretta della biblioteca digitale la vede come un semplice repository di contenuti digitali, che vengono memorizzati alla fine del loro ciclo di vita. Questa visione ristretta della biblioteca digitale può costituire un ostacolo per la gestione dei dati di ricerca. I ricercatori hanno infatti bisogno di un servizio a tre livelli: un archivio digitale individuale, un archivio da condividere con una comunità scientifica conosciuta, un archivio digitale di dati pubblicati e aperti per il ri-uso. Le biblioteche digitali possono essere la soluzione giusta per questo bisogno, ma devono essere concepite con un approccio più ampio e viste come sistemi che abbracciano l’intero ciclo di vita della ricerca, per gestire diversi risultati della ricerca e consentire il loro ri-uso.
Possiamo caratterizzare la digital scholarship come una modalità di ricerca che è:
- ad alta intensità di dati: genera e spesso utilizza grandi volumi di dati;
- collaborativa: coinvolge ricercatori in più istituzioni e spesso a livello transnazionale e interdisciplinare;
- Grid-enabled: utilizza reti e strumenti software e hardware ad alta capacità.
È chiaro dagli studi condotti finora che fornire un’efficace gestione dei dati di ricerca in tutto il ciclo di vita dei dati, richiede investimenti non banali. Il ritorno su questo investimento è rappresentato da una ricerca di qualità superiore, dall’accesso più semplice e quindi più economico ai dati esistenti, dalla riduzione della necessità di ripetere le indagini per generare dati e dalla facilitazione di nuovi argomenti e approfondimenti di ricerca. L’OECD nel rapporto “Principles and guidelines for access to research data from public funding” evidenzia che l’investimento pubblico per l’Open Access ai risultati della ricerca ed il ri-uso dei dati di ricerca ha un ruolo sociale:
“Sharing and open access to publicly funded research data not only helps to maximise the research potential of new digital technologies and networks, but provides greater return from the public investment in research.” (OECD, 2007)
I dati di ricerca sono diventati una risorsa di ricerca primaria, che spesso richiede un accesso continuo nell’ambiente dinamico che caratterizza la diversa modalità di produzione di conoscenza dei ricercatori, caratterizzata da prodotti transitori, standard di breve durata, accesso e ri-uso da diversi dispositivi, incluso i dispositivi mobili.
La maggior parte dei ricercatori scientifici, rispondenti al questionario diffuso dal progetto “Innovations in scholarly communication“, coordinato da Jeroen Bosman e Bianca Kramer dell’Università di Utrecht, salva i dati e riutilizza questi dati in archivi personali o archivi del Dipartimento. I ricercatori non si limitano a dover memorizzare i dati ma necessitano di un accesso continuo ai loro dati, dal momento in cui gli esperimenti sul campo vengono progettati, attraverso l’analisi ed infine la pubblicazione finale. Tuttavia, gli strumenti messi a loro disposizione spesso da privati, supportano l’analisi dei dati molto meglio di quanto non facciano le funzionalità di conservazione della biblioteca digitale nella visione ristretta. Di conseguenza, i ricercatori spesso archiviano i dati con una documentazione minima e fanno poco per la conservazione dei dati a lungo termine. L’attuale approccio alla gestione dei dati di ricerca è in gran parte responsabilità individuale e/o locale ma non offre un supporto adeguato per l’accesso ed il ri-uso futuri.
I dati di ricerca concettualmente devono essere considerati come una costruzione di conoscenza “sociale”, che si evolve da una base teorica (le diverse metodologie di ricerca delle discipline) ed ha molti livelli di interpretazione successiva che interagiscono e trasformano i dati. La metodologia di ricerca ad esempio si basa su:
Osservazione: dati acquisiti in tempo reale, ad esempio dati dei sondaggi, immagini.
Sperimentazione: i dati provenienti da apparecchiature di laboratorio, spesso riproducibili, ad esempio sequenze di geni.
Simulazione: dati generati da test in cui modelli e metadati sono più importanti dei dati di output. Ad esempio, modelli climatici, modelli economici.
Compilazione: spesso i dati sono aggregati da diverse fonti, ad esempio, estrazione di testo e dati, banche dati, modelli 3D.
Riferimento: raccolta di set di dati più piccoli (sottoposti a peer review), pubblicati e curati. Ad esempio, banche dati di sequenza genica
Le biblioteche si sono occupate da secoli di risultati della ricerca basati su testi statici ed ora devono affrontare la sfida di adattare la loro funzione per dati dinamici, rendendoli accessibili e riutilizzabili in modo affidabile. Le biblioteche digitali dei dati devono considerare sei categorie di requisiti: 1) la capacità di creare e gestire i dati, 2) pulire e verificare i dati , 3) documentare il contesto dei dati per l’interpretazione successiva, 4) integrare i dati da più fonti, 5) analizzare i dati e 6)preservare i dati.
L’assenza – al momento – di un quadro nazionale coerente per la gestione dei dati non significa che in Italia non ci siano iniziative per la gestione dei dati, alcune anche di rilievo internazionale. Alcune aree tematiche scientifiche sono più avanti, ma ci sono esperienze anche nel settore umanistico e sociale. Nel primo Convegno italiano a Firenze nel 2016 di RDA Research Data Alliance sono state presentate significative esperienze italiane nella cura dei dati (vedi il resoconto del Convegno nell’articolo di Vellani e Lepore
Servizi di supporto delle biblioteche digitali di dati
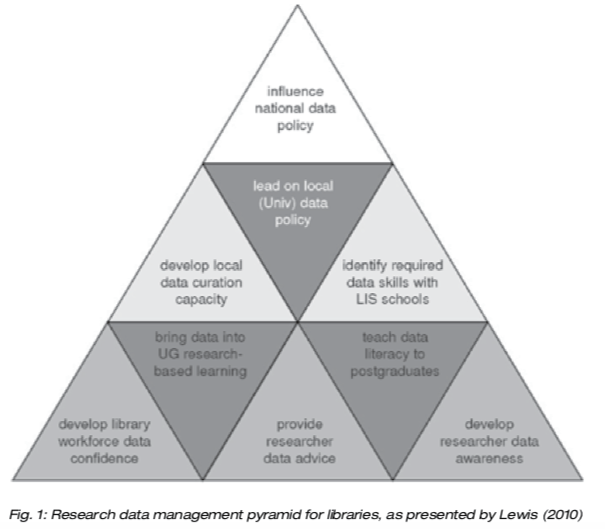
I servizi di supporto sono stati rappresentati come una piramide da Lewis (2010), riflettendo la visione ampia di “biblioteca digitale”.
.
Alcune biblioteche accademiche hanno iniziato a creare e offrire servizi di supporto per la gestione dei dati di ricerca. Per essere capaci di realizzare un servizio di supporto, le biblioteche devono allearsi e collaborare con tutti gli stakeholders, come uffici della ricerca, Dipartimenti, centro di calcolo, editori, finanziatori eccetera. Lyon (2007, p. 9 e p. 55) nel rapporto presentato al JISC ha evidenziato con chiarezza tutti i ruoli che sono coinvolti nella gestione dei dati di ricerca, con le rispettive responsabilità.
Ci sono della attività tuttavia che le biblioteche digitali nella visione estesa possono fare meglio di altri settori. Nella piramide di Lewis (2010) sono raggruppate in tre aree di colore diverso circa nove attività: quelle alla base sono attività di orientamento e sono in genere le prime ad essere organizzate, quelle centrali si concentrano nella gestione dei dati ed il supporto al Data Management Plan, quelle in alto riguardano le attività di governo e si concentrano sulle politiche e linee guida necessarie a livello locale, nazionale ed internazionale.
Concentrandosi sulle attività di gestione dei dati di ricerca, le biblioteche digitali possono conservare i dati, esporli in modo intelligibile, facilitare l’accesso, renderli ri-usabili ed, allo stesso tempo, consentire di interagire coi dati. La progettazione di biblioteche digitali per dati statici è già complicata a causa della varietà di tipologie di dati e della complessità dei diversi contesti. La biblioteca digitale per dati dinamici deve affrontare tutti questi problemi, ed inoltre deve gestire i diversi set di dati prodotti in ciascuna fase del ciclo di ricerca (vari risultati di ricerca e non solo dati), favorendo funzionalità di condivisione, collaborazione e cooperazione.
Molte biblioteche digitali stanno fornendo repository istituzionali per consentire ai propri utenti di pubblicare e archiviare set di dati o stanno aiutando i ricercatori a identificare altri repository appropriati come depositi per fonti di finanziamento specifiche, per discipline o altri domini.
Per preservare l’integrità e il valore durante tutto il ciclo di vita dei dati, è necessario un livello maggiore di interoperabilità tra le biblioteche di dati e repository accademici. Questo è assicurato dagli standard preservazione, come il modello di riferimento Open Archival Information System (OAIS) e le certificazioni di archivi digitali affidabili come ISO 16363 e il Data Seal of Approval.
Un’attività rilevante è svolta delle biblioteche digitali per la documentazione, la citazione ed i metadati dei risultati di ricerca. Dati e documenti hanno un ID univoco assegnato al momento della creazione che rimane con loro indipendentemente dalle modifiche al nome del file, evitando confusioni con file con nomi simili. Tutti i file hanno metadati appropriati tra cui creatore, data di creazione, ultima modifica, tipo di file, informazioni assegnate al momento della creazione. I file possono essere taggati in base al loro contenuto, raggruppandoli e facilitando la loro rapida identificazione e recupero durante le ricerche. Ci sono diversi schemi che vengono utilizzati, per avere un orientamento è molto utile la dichiarazione del Data Citation Synthesis Group Force11 (2014): Joint Declaration of Data Citation Principles.
Altri servizi avanzati possono essere forniti dalle biblioteche digitali, che sono esse stesse creatrici di contenuti o aggregatrici di diverse fonti di dati. In alcuni casi si parla di biblioteche digitali come Virtual Research Environment (VRE). Ad esempio l’infrastruttura CENDARI (Collaborative EuropeaN Digital Archive Infrastructure) fornisce e facilita l’accesso agli archivi e alle risorse esistenti in Europa per lo studio della storia medievale e moderna dell’Europa, attraverso lo sviluppo di un “ambiente di ricerca”. Gran parte della ricerca storica e della ricerca umanistica in generale, è caratterizzata da un processo noto come concatenamento – disegno iterativo di conclusioni che vengono verificate da prove scoperte nel passaggio logico successivo. Il processo di creazione della conoscenza della ricerca storica deve consultare un corpus di dati storici eterogenei che richiede tempo, e il tempo aumenta in modo esponenziale se i record si trovano in paesi diversi, scritti in lingue diverse, a volte disseminati da conflitti e spostando i confini politici su centinaia di anni. Inoltre, i documenti d’archivio sono spesso imperfetti e assolutamente non scientifici per complicate motivazioni umane che li hanno creati. Pertanto, il potenziale di un’infrastruttura che integri le risorse di archiviazione per la ricerca storica è stato enorme, per consentire l’esplorazione (chiamata data mining) di connessioni tra eventi distanti nel tempo e nello spazio e tendenze a livello macro.
Conclusioni
Per comprendere gli strumenti e i servizi appropriati necessari per le biblioteche digitali di dati, è ancora necessario approfondire lo studio delle diverse pratiche scientifiche associate all’archiviazione, al recupero dei dati ed alla loro produzione, analisi e interpretazione. E’ questo un nuovo ruolo delle biblioteche digitali, che dovrebbero tutte cimentarsi in servizi di supporto in tutte le fasi della ricerca. In conclusione vorrei evidenziare che le buone pratiche delle biblioteche digitali indicano la necessità di costruire comunità di pratica. I bibliotecari si connettono tra loro e con una più ampia comunità di ricercatori, informatici, finanziatori, editori e altri interessati per sviluppare soluzioni e condividere i dati di ricerca. In Italia un esempio di Comunità di pratica è il gruppo IOSSG (Italian Open Science Support Group), che è sorto spontaneamente ed ha elaborato un originale concetto di servizio di supporto basato su un Single Point of Entry, un singolo punto di accesso per il ricercatore per vari aspetti dei servizi di supporto. A livello internazionale c’è la Comunità di pratica RDA (Research Data Alliance), organizzazione nata nel 2013 mettendo insieme della Commissione europea, della National Science Foundation (Stati Uniti) e da Australian Government’s Department of Innovation, con l’obiettivo di costruire l’infrastruttura sociale e tecnologica per consentire la condivisione aperta dei dati.
Testo della presentazione al Convegno IDEM, il giorno 8 maggio 2018
Riferimenti bibliografci
Force11 Data Citation Synthesis Group: Joint Declaration of Data Citation Principles. Martone M. (ed.) San Diego CA: FORCE11; 2014
Lewis, M.J. (2010) Libraries and the management of research data. In: McKnight, S, (ed.) Envisioning Future Academic Library Services. Facet Publishing , London , pp. 145-168.
Lyon, E. (2007) Dealing with data. Joint Information Systems Committee.
